The Overclock Illusion: Why Aggressive IGP Tuning is Killing Your Network
Every network engineer wants sub-second convergence.
But it's a common trap to assume BGP handles this automatically. Because BGP manages the vast majority of overlay routing, many assume the underlying IGP speed is of secondary importance.
This is a massive vulnerability.
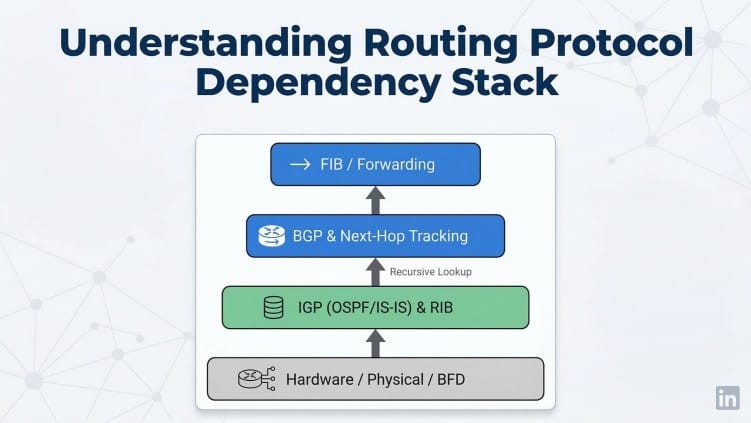
BGP is not an independent entity. Its operational speed relies entirely on the IGP. When a topology changes, BGP Next-Hop Tracking waits for the IGP to recalculate the shortest path before it can update.
If your OSPF takes 40 seconds to detect a dead neighbor, your BGP traffic drops into a black hole for 40 seconds.
⚠️ The Overclock Illusion
To fix this, engineers try to "overclock" the routing protocol. They drastically reduce hello and dead intervals. They drop the SPF initial wait timer to absurdly low values.
But they forget a fundamental rule of routing: Protocols react instantly to direct interface failures. If a physical cable is cut, the interface goes down, generating a hardware interrupt that tears down the adjacency immediately - completely bypassing the dead timers.
This means aggressive timer tuning is only trying to solve indirect or "silent" failures (like a transparent transport switch dying in the middle of a path).
Attempting to catch silent failures by forcing your CPU to process hyper-aggressive software timers creates the Overclock Illusion. The network looks faster, but you've created three invisible landmines:
💣 The Three Landmines
1️⃣ CPU Exhaustion & IPC Starvation
Every routing state change triggers an SPF run. At aggressive intervals, the software tries to run the SPF algorithm for every single state change individually. This pegs the CPU at 100% and starves the Inter-Process Communication.
2️⃣ Transient Micro-Loops
Updating the hardware Forwarding Information Base (FIB) is a localized hardware action. Router A might update in 20ms. Router B might take 60ms. During that 40ms gap, they route traffic back and forth at each other. Packets bounce endlessly until their Time-to-Live expires.
3️⃣ Breaking High Availability
If a primary supervisor fails, Stateful Switchover (SSO) takes up to 10 seconds to transition. If your dead timer is set to 3 seconds, remote neighbors tear down the adjacency before the switchover finishes. You just turned a seamless failover into a massive outage.
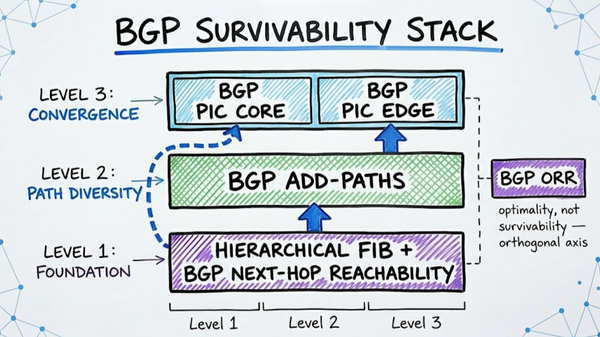
The Decoupled Speed Framework
Stop manipulating raw protocol timers. Instead, implement these two technologies:
BFD (Bidirectional Forwarding Detection): A dedicated, lightweight hello protocol that runs entirely in hardware ASICs. It detects failures in 50-300ms without touching the routing protocol at all.
BGP PIC (Prefix Independent Convergence): Pre-computes and pre-installs backup paths in the FIB before any failure occurs. When a failure is detected, the hardware just flips a single pointer, rescuing traffic instantly regardless of routing table size.
Let the hardware handle the speed.
Let the IGP handle the math.
👇 Have you ever inherited a network brought down by overly aggressive timers? Are you fully on the BFD and PIC train yet? Let's debate in the comments.