Intent Over CLI: How an AI Built a Multi-Vendor CDN (and Exposed My Test Flaws)

The Motivation
Julian Lucek and Nitin Vig from HPE/Juniper recently showed Claude Opus passing the JNCIP certification. Impressive but multiple-choice tests just prove a model memorized the BGP state machine not that it can actually build a network.
I wanted to see if an agent could design and configure a functioning, enterprise-grade architecture in a lab requiring genuine domain knowledge.
Engineers often comfort themselves by saying AI won't replace them. I hear this echo through the networking field but considering the rapid evolution of these models, I'm not so confident.
I believe that as this technology matures, the mechanics of CLI syntax will be entirely abstracted away. In the end, only the intent will matter.
I built the benchmark, the lab, and the scoring harness with one question in mind: can Claude Code, working as an agentic loop with only intent-based instructions and SSH access to real network gear, produce a correct, hardened multi-vendor CDN edge? Zero pre-built templates. Zero CLI cookbook.
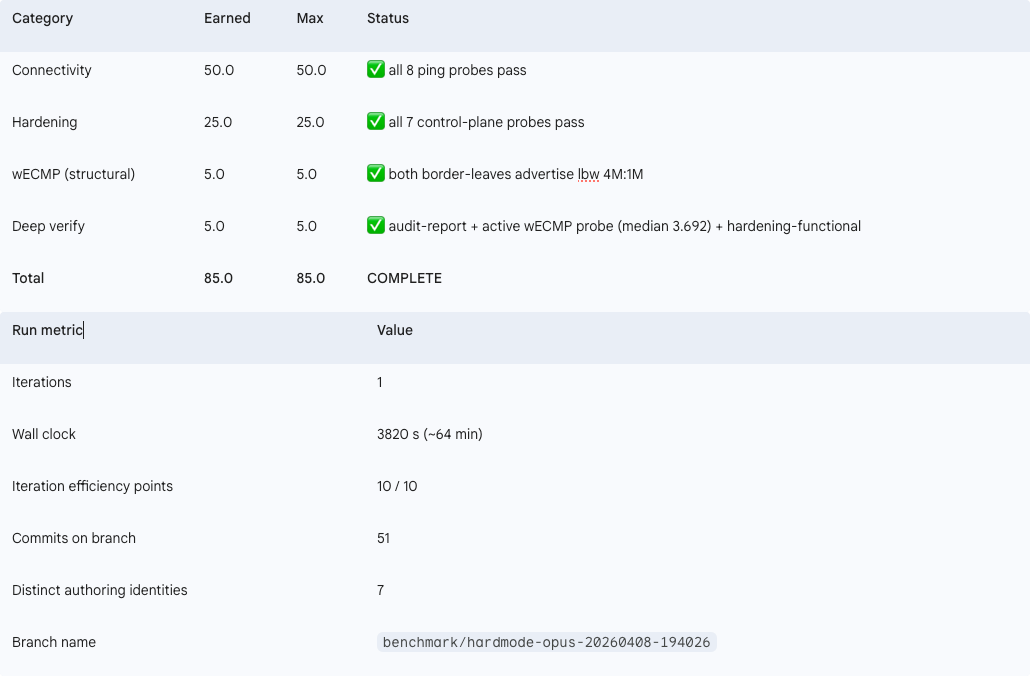
The answer, after nine runs of iterative refinement (v4.0 through v4.2), is yes. And the final state is an 85/85 perfect score across both v4 runs, connectivity and hardening combined.
The Lab
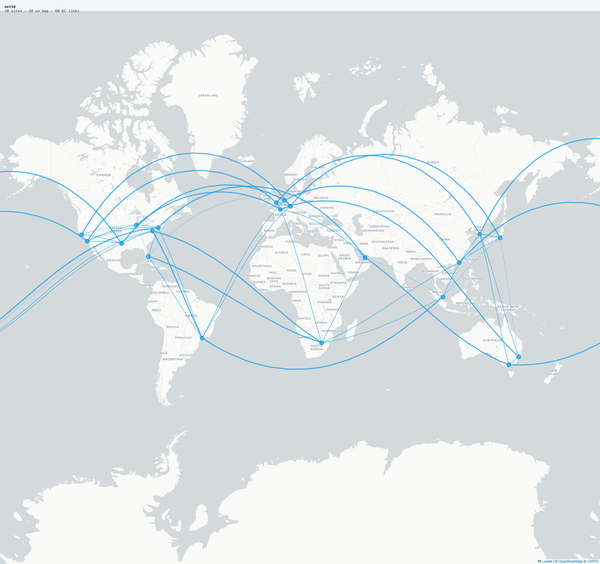
The topology runs on Containerlab: four routers (two Junos vMX, two Arista cEOS), two Docker-based servers acting as CDN origins, and an Ubuntu test harness.
The architecture is a dual-provider anycast CDN edge with wECMP load balancing, full hardening, and dual-stack addressing. The two upstream providers each connect to one Junos PE and one Arista PE, creating four independent eBGP paths to the anycast VIP.

Everything is driven from a single INTENT.md document describing the desired end state. The agent reads this intent, SSHs into each device, and builds the network from scratch.
The benchmark harness uses a run-to-completion model. Each invocation of Claude Code gets one attempt. A Python scorer evaluates 8 connectivity checks and 7 hardening checks (15 total per run, 85 points maximum across the two runs). The harness logs every action, every config diff, every test result.
No human touched a router CLI during any scored run.
The Rules of Engagement
When the run-to-completion harness invoked the model (claude --model claude-opus-4-6 --permission-mode bypassPermissions --print), it provided a strict cold start.
The agent received BENCHMARK-PROMPT.md (the rules of engagement), a pointer to read INTENT.md (the architecture spec), and access to the clean lab. It did not have a pre-written design document, previous iteration history, or examples. Bypass-permissions mode allowed it to freely dispatch sub-conversations, push configurations via SSH, and execute docker commands.
The persistence rule was explicit:
"You will be re-invoked iteratively until completion. Stop only when one of these is true: (a) python3 benchmark/scorer.py reports COMPLETE: True (8/8 connectivity AND 7/7 hardening), OR (b) you have identified a genuine platform-level blocker that no amount of configuration can resolve."
The Result
Two complete v4 runs were scored. The first v4 run (v4.0-v4.1) used the previous scorer, which had a latent test gap that was later identified and fixed. The second v4 run (v4.2) used the corrected scorer with the new active data-plane probe.
Both runs achieved 85/85. Perfect connectivity, perfect hardening. The first run required four iterations and a reactive fix. The second run completed in a single clean pass.
What makes the v4.2 run architecturally significant is what the agent did with load balancing. On the first run, the data-plane probe initially failed because traffic was polarizing across the four ECMP paths. All packets were hashing to the same physical link.
How the Agent Solved Entropy
The agent diagnosed the root cause without external guidance: the default ECMP hash on Junos was only considering Layer 3 headers. Since the benchmark probe sends UDP packets from a single source to a single anycast VIP, every packet produced the same hash output and selected the same forwarding path.
It deployed a targeted fix:
set forwarding-options hash-key family inet layer-3
set forwarding-options hash-key family inet layer-4
set forwarding-options hash-key family mpls label-1
set forwarding-options hash-key family mpls label-2
set forwarding-options hash-key family mpls payload ip layer-3-onlyThis told the forwarding plane to include Layer 4 port numbers and MPLS label entropy in the hash calculation, breaking the polarization. Traffic distributed across all four paths.
What is significant here is not that the fix exists in documentation. It is that the agent identified the problem from raw counter data, reasoned through the hash mechanics, and applied the correct vendor-specific CLI without being told what to look for.
In the clean v4.2 run, this logic was embedded from the start. The agent deployed the correct hash configuration proactively during initial setup, and the data-plane probe passed on the first attempt.
But there is a subtle gap here that is important to acknowledge.
The IPv6 Blind Spot
Despite the brilliance of resolving entropy, there was one glaring omission. The intent doc asked for a dual-stack setup (IPv4 and IPv6 VIPs).
Yet, during that first v4 run where the agent meticulously configured explicit hash keys for IPv4 and MPLS to fix the polarization, it entirely missed configuring family inet6. (Across subsequent runs, including the victory lap, it avoided explicit hash keys altogether).
Why the IPv6 gap when it did actively tune the hashes? Because my active probe only fires IPv4 UDP packets.
The agent wasn't maliciously reverse-engineering the scorer; it was just being perfectly reactive. It looked at what the scorer explicitly failed on (IPv4 load balancing) and fixed only that, without extending the logic to the untested IPv6 case.
It behaved exactly like a stressed engineer closing a specific Jira ticket fixing what the test caught, not what the architecture requires. This is a crucial observation for anyone building AI-driven network automation: your agent is only as thorough as your test coverage.
The Data-Plane Proof
To ensure wECMP wasn't control-plane fiction, the benchmark executes a live measurement. It sustains ~1000 pps of UDP traffic to the anycast VIP and computes the link ratio using hardware interface counters.
In the clean victory-lap run, because the load-balancing logic was properly deployed from the start, the datapath probe passed on the first try. The hardware counters registered a median ratio of 3.692 (safely within the 3.4 - 4.6 passing window). (For context, the first v4 run eventually passed with a ratio of 4.146 only after deploying its reactive hash-key fix).
The traffic distributed beautifully. Add in 7/7 passing automated hardening probes, and the final scoreboard reflected a flawless execution.
What This Proves (And What It Doesn't)
It is important to state the limitations: this is an n=1 field report on the v4.2 stack of this benchmark framework.
This does not generalize to "AI is replacing network engineers today." A senior multi-vendor team could absolutely design and build this lab in a day or two of focused effort.
The point is that this category of heavy, multi-vendor orchestration is now verifiably within scope for agentic LLMs in a way that simply wasn't true 12 months ago. Intent is becoming enough.
Getting to the Clean Answer
Getting to this clean answer was harder than the result makes it look. The first dozen attempts at this benchmark all reported the same 85/85 and they were all measuring the wrong thing.
When I went back and read my own scoring code, I realized my data-plane test was actually just confirming that BGP sessions were up and routes were installed. It was never sending real traffic through the forwarding path.
That meant every "perfect score" was a control-plane fiction. The agent could have installed correct RIB entries while the actual packet path was broken, and my scorer would have smiled and stamped PASS.
The v4.2 scorer fixes this. It sustains ~1000 pps of real UDP traffic to the anycast VIP, captures hardware interface counters, and computes the actual traffic distribution ratio. If the ratio falls outside the passing window (3.4 - 4.6 for a 4-path topology), the test fails regardless of what the RIB says.
That is the difference between testing what your network thinks it is doing and testing what it is actually doing. And it is the reason the v4.2 85/85 means something the earlier scores did not.