The Enterprise-as-a-CDN: Mastering Anycast Ingress from the Trenches
The following blueprint is not a theoretical lab exercise or a "cloud-native" wish list. It is a methodology honed over years of managing a sovereign enterprise backbone where we own our Autonomous System (AS), our IPs, and our compute rather than relying on public cloud abstraction. This approach is not the "absolute truth" for every organization. However it has proven to be devastatingly effective both from a cost perspective (by actively saturating our own compute capacity rather than paying for idle redundancy) and from a security perspective (by mitigating DDoS attacks architecturally).
In my previous articles, we explored using BGP Flowspec as a surgical tool for migrations and why relying on stateful firewalls for ingress is essentially a performance suicide pact. Now, let's look at the "Final Boss" of architecture: transforming your backbone into a private Anycast CDN.
By having Load Balancers (LBs) inject /32 service prefixes directly into your backbone, you turn your network into a distributed, self-healing service mesh that functions exactly like a private CDN - but entirely under your control.
1. The Challenge: Predicting Traffic Gravity
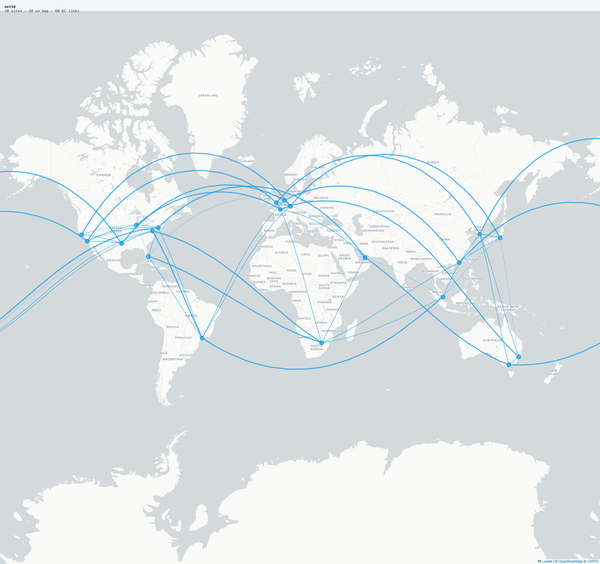
In an Anycast model where we use latency as the IGP metric, the traffic flows to the "closest" node. However BGP is not inherently load-aware; it follows the "path of least resistance." This creates a massive dependency on your Inbound Traffic Patterns.
You must know exactly how your consumers - whether "Eyeballs" (residential users) or "Silicon" (other clouds/API clients) - reach you.
- The Concentration Trap: If you plug both a high-capacity local peering exchange and a major transit provider into the same PoP, it will attract a massive disproportionate load. It becomes the shortest path for the majority of your traffic. I've seen nodes crushed under their own success because engineers didn't account for this carrier capillarity.
- The Inbound Influence: Your choice of transit and peering directly determines which PoP processes the traffic.
- The Balancing Act: Your peering and transit strategy is the real knob you turn to control traffic distribution across your Anycast fabric.
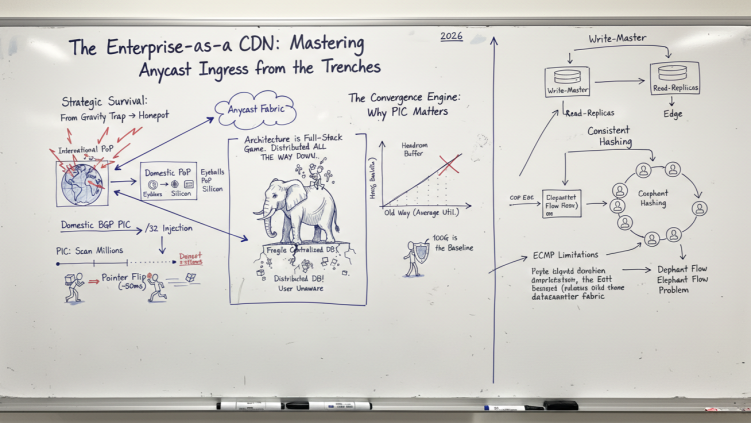
2. Strategic Survival: From "Gravity Trap" to "Honeypot"
The "Gravity Trap" described earlier isn't just a risk; once you've spent enough time in the trenches you learn to turn it into your primary defensive strategy. By intentionally orchestrating traffic gravity you can architect your network to naturally isolate massive volumetric attacks.
- Early Mitigation: Use Flowspec or ACLs at the network edge to drop unnecessary protocols. For a standard HTTP farm, you can kill UDP volumetric attacks before they ever touch your compute layer.
- Capacity as Security: Stop sizing ports based on average utilization. Now that we are in 2026, 100G must be your baseline. High-capacity ports provide the headroom buffer necessary to absorb an initial hit, giving you time to analyze the flow and apply filters before the link saturates and you go dark.
3. The Intentional Honeypot: Weaponizing Gravity
The Gravity Trap isn't just a risk - it is a tool. We know that Tier-1 providers are often DDoS superhighways. Every major attack originates from the same few global transit providers.
The Strategy:
- You set up a Domestic PoP with inbound connectivity strictly via domestic ISPs or local peering, avoiding global transit on this specific node.
- The Split: You serve your core domestic audience from this DC, while a second DC connected to international Tier-1/Tier-2 carriers serves the rest of the world.
- The Shield: When a global DDoS hits, the "garbage" traffic will naturally gravitate toward the international Tier-1 DC by design. You can let that site "die" (or redirect it to scrubbing) while your domestic customers remain on the "clean" dedicated datacenter.
- Automation via Communities: You can automate this domestic-only mode using BGP Communities. By binding a community that instructs your local providers not to announce your prefix to their Tier-1 upstreams, you effectively mute the gravity of that PoP for the global internet during an attack.
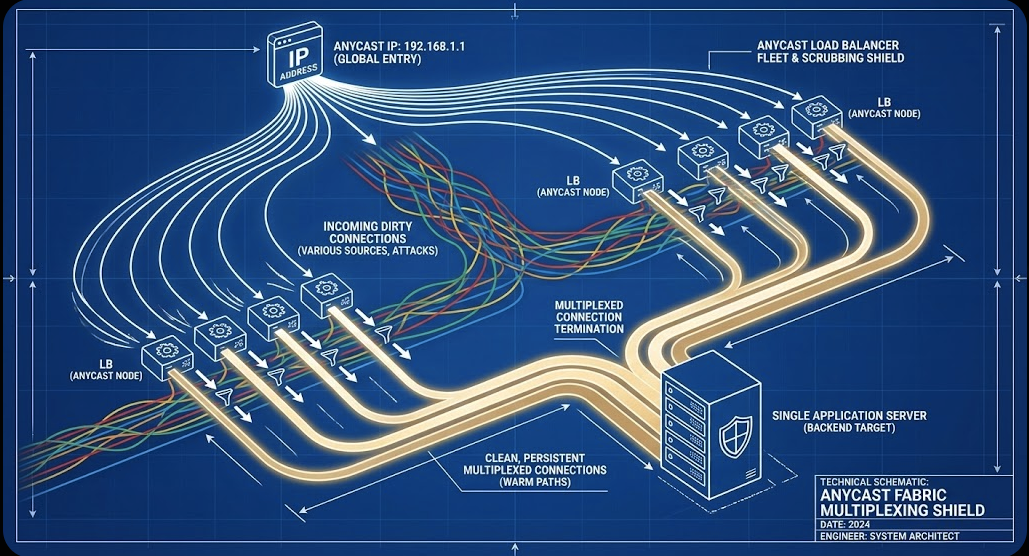
4. Protecting the Edge: The Multiplexing Shield
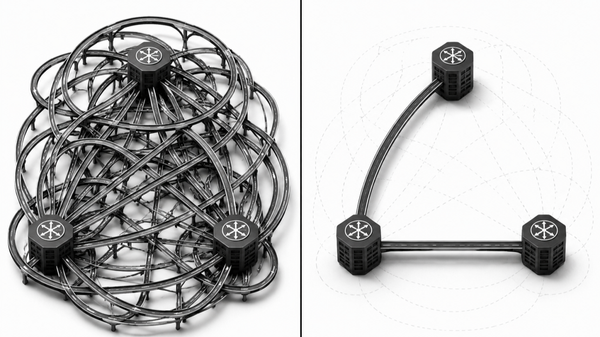
Moving security logic to the Load Balancer layer within the Anycast fabric solves the "Ingress Stateful bottleneck." Instead of one "big box" bottleneck, you deploy a fleet of small instances advertising the same IP via BGP. The backbone spreads the load naturally across the fleet.
The Multiplexing Advantage: The LB accepts thousands of connections at the edge and routes them over a few "warm" persistent connections to the backend, saving massive CPU cycles on your application servers.
5. Traffic Engineering: Internal vs. External Precision
To prevent the "Hot Potato" from becoming a "Burnt PoP," we use BGP's native toolset - but we must apply it to the correct layer.
- The /24 Stability: We avoid prepending or manipulating the external /24 announcement whenever possible. External prepending is often a blunt, ineffective tool because upstream networks prioritize their own policies over your path length, and constant changes here trigger global BGP reconvergence.
- The /32 Scalpel: Instead, we apply AS Path Prepending or route withdrawals strictly to the /32 service prefix injected by the Load Balancer into the internal backbone. Externally, the user still connects to the closest ingress (keeping latency low). However, internally, the router sees the local /32 disappear and automatically redirects the packets across the backbone to the next-closest healthy Load Balancer. The ingress doesn't change, but the service execution moves seamlessly.
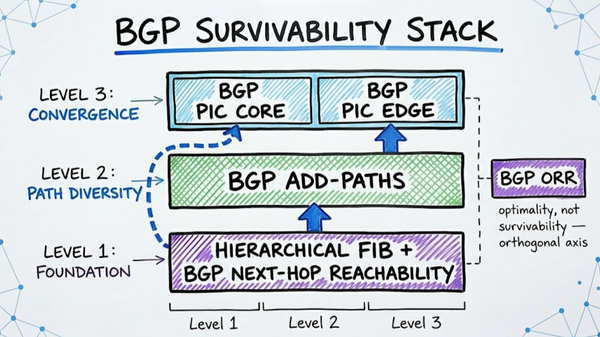
6. The Convergence Engine: Why PIC Matters
Architecture is only half the battle. To ensure these redirections happen in under 50ms, BGP Prefix Independent Convergence (PIC) is non-negotiable.
Without PIC, the router scans millions of prefixes one-by-one during a failure. With PIC, we pre-install a backup path in a hierarchical FIB structure. When a failure is detected - ideally via hardware Loss of Signal (LOS) which reacts in ~2-5ms - the router performs a single pointer flip. Traffic is redirected to the next-closest Anycast node before the user even notices a blip.
The Verdict: Architecture is a Full-Stack Game
Building your own CDN using Anycast is about moving beyond traditional capacity planning. There is also the elephant in the room that usually stems from Stateful Firewalls / Load Balancers - the concern that if a packet for the same session moves from PoP A to PoP B, the connection dies.
In reality, this setup fits perfectly on short-lived TCP sessions. While long-lived sessions can be a challenge, this is often more of an application issue than an infrastructure one. To be truly effective, the architecture must be consistent at every layer: the backend, and especially the database stack, must be designed for a distributed world. You cannot have a global Anycast ingress sitting on top of a fragile, centralized database.
Have you embraced Anycast services yet?
What's Next?
This article covered inbound gravity. But what happens inside the fabric once traffic lands?
- "Global Spraying": Alleviating hot potato routing by forcing equal traffic distribution regardless of IGP metric.
- "Consistent Hashing at Scale": How to ensure the same user hits the same cache node in a stateless Anycast world.