One IP, Many Ports, Zero Downtime: The BGP Flowspec Story Behind Our Migration

The Challenge: When Granularity Is Your Only Option
We were dealing with a legacy "beast" of a platform: a critical and systemic service running on traditional infrastructure, glued behind a single IP address. This IP hosted hundreds of distinct TCP ports, each representing different customers, protocols, and hard-wired IoT clients.
The constraints were absolute:
- No DNS Control: Many clients connected via hardcoded IPs. Changing the destination IP was impossible.
- No Proxy Layer: The obvious answer would be to front the service with a load balancer or reverse proxy. But these were raw TCP flows, not HTTP. Stateful inspection at this scale would have introduced latency, added a failure domain, and required re-engineering client timeout behaviors we couldn't touch. We needed transparency, not interception.
- The "All-or-Nothing" Trap: With standard routing, a subnet exists in one place. You can't advertise a /32 from two locations simultaneously without breaking sessions. Moving the whole service at once was too risky given the number of customers and protocols involved.
We needed to migrate traffic for a single IP address across two different infrastructures, port by port, without introducing a proxy layer or a load balancer.
But we had an ace up our sleeve: BGP Flowspec.
The Solution: Flowspec + Anycast + MPLS
We were already using BGP Flowspec to mitigate DDoS attacks, but we realized it could be repurposed. Flowspec injects logic directly into the router's forwarding plane, allowing us to bypass the standard RIB lookup.
Here is the architecture we built to make this work:
1. The Redirection (Flowspec as Policy Routing)
Standard BGP routes based on destination IP. Flowspec routes based on n-tuple matching. We configured Flowspec rules to match specific TCP ports (the services ready to migrate). The action was not to drop traffic (as in DDoS mitigation), but to rewrite the BGP Next-Hop.
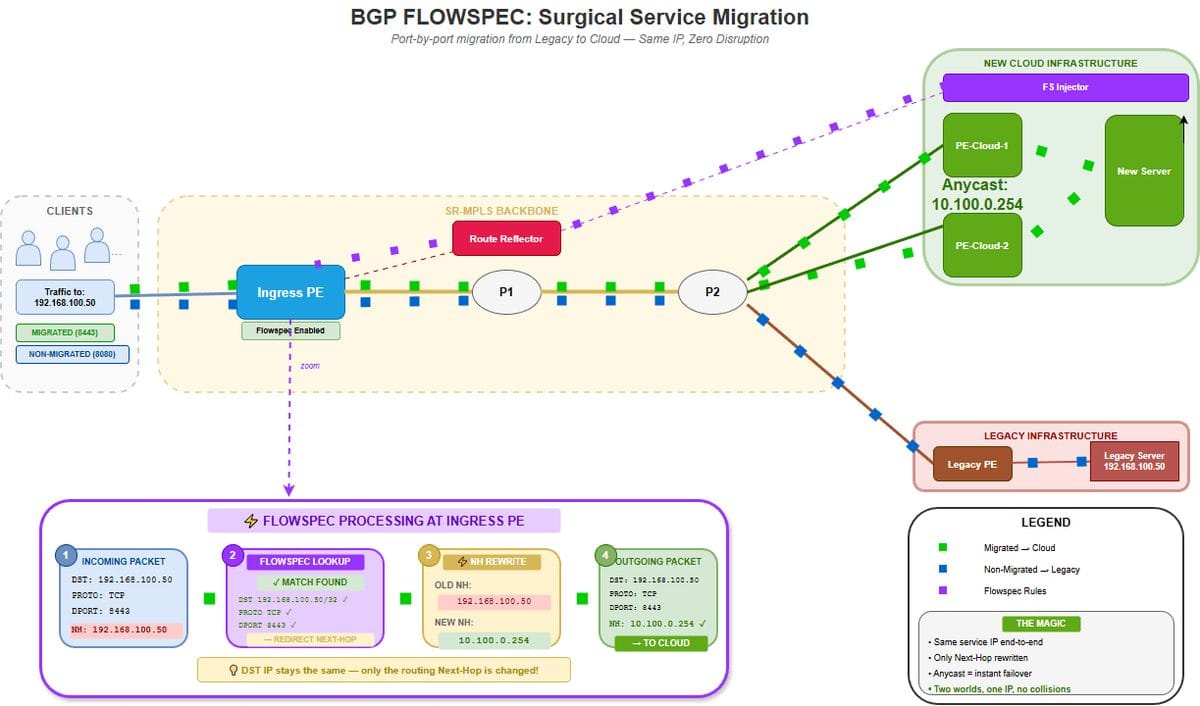
Match: Dest: 192.0.2.50, Proto: TCP, Port: 8443
Action: redirect-to-nexthop: 10.100.0.254 (The Anycast IP)2. The Destination (The Anycast Anchors)
We introduced a loopback interface on every new PE router advertising the same Anycast IP (10.100.0.254). This was critical for resilience: if we had redirected to a single physical router and that router failed during the migration, the migrated customers would go dark. By using Anycast, if one new PE failed, the Flowspec redirection would simply resolve to the next available PE advertising that label. It made the migration path self-healing.
3. The Transport (The MPLS Label Stack)
This is the critical piece that prevented routing loops. When Flowspec rewrites the Next-Hop, the ingress router resolves the path to the New PE (Anycast IP) and imposes the correct transport labels. The core routers switch the packet to the new cloud fabric. When the packet arrives, the new PE decapsulates it and looks up the IP in its local VRF. Because the new platform is listening on that IP locally, the packet is delivered.
4. The Split Brain (L3VPN)
- Legacy PE: Advertises the Service IP /32 to the WAN.
- New PE: Has the Service IP configured locally but does not advertise it to the WAN.
- The Result: Default traffic flows to the Legacy PE. Only packets matching the Flowspec rules get redirected to the New PE.
The Danger: Flowspec Is a Global Kill Switch
Every experienced network engineer knows this horror story. We recall those major Tier-1 backbone outages triggered by a single mis-typed Flowspec rule - an engineer trying to block a small DDoS, but accidentally omitting a subnet mask or a protocol-match. That one small slip blew up into a full-blown control-plane failure, taking down large swathes of the Internet for hours.
The mechanism of failure is terrifyingly efficient:
- The Typo: An engineer intends to drop traffic to 1.2.3.4/32 on Port 80. They accidentally type 0.0.0.0/0 on Port 179.
- The Propagation: Unlike an ACL that you apply to one interface, BGP Flowspec is a routing update. It propagates to every router in your backbone at the speed of light.
- The Blackout: Within seconds, every router in the network installs a hardware filter dropping all BGP sessions globally.
- The Loop: As BGP sessions bounce, each router attempts to re-establish them - which immediately re-installs the same poisonous rule. The backbone is now in a self-reinforcing failure loop, and you've severed the very path you need to fix it.
It's one of those moments where you silently thank the universe for a real out-of-band management network (if you have one).
Flowspec is a "Global Kill Switch" if mishandled. It bypasses the safety checks of normal routing tables. Using this for a migration felt like using a nuclear cannon to light a birthday candle.
Safety Architecture: Caging the Beast
To use this weapon safely, we had to assume that human error is inevitable and that automation will eventually have a bug. We built a Defense in Depth strategy to ensure that even if we tried to destroy the network, the network would refuse to cooperate.
Layer 1: The Terraform Interface (GitOps) - We masked the complexity behind a declarative Terraform module. Service owners didn't touch router configs; they submitted Pull Requests. A simple, auditable YAML input was the only interface to the Flowspec subsystem.
Layer 2: Pipeline Logic & Validation - The CI/CD pipeline parsed the Terraform plan. It enforced logic that a human might miss:
- Is the destination IP valid?
- Is the port within the allowed range?
- Crucially: Is the Next-Hop the authorized migration Anycast IP? (Preventing redirection to blackholes or loops.)
Layer 3: Network-Side Hard Filters (The Fail-Safe) - Automation can have bugs. We assumed the pipeline might fail. We configured every backbone router with BGP Flowspec acceptance policies. This was our insurance policy against the "Global Kill Switch" scenario.
We applied a policy on the BGP sessions that acted as a firewall for routes:
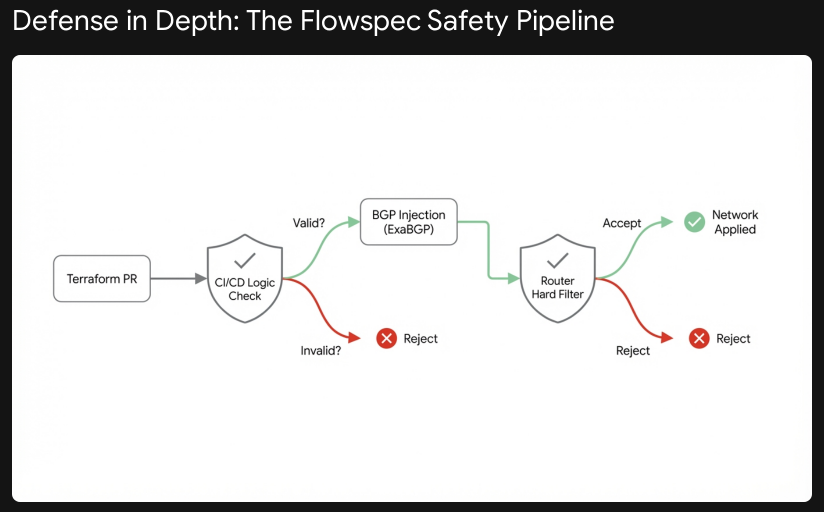
- Reject any rule where the destination is NOT the Legacy Service IP (192.0.2.50/32).
- Reject any rule where the action is NOT redirect-to-nexthop 10.100.0.254.
- Reject any rule that attempts to drop traffic (preventing accidental blackholing).
Even if a rogue engineer or a broken script tried to push a wildcard rule to drop the internet, the routers would silently discard it, and finally restricted by ingress filter.
The Final Step: Where Success Meets Failure
After weeks of redirecting flows and validating each service port-by-port, every individual migration was complete. Traffic was flowing correctly through the new infrastructure. But we weren't done yet.
The last step remained, and it was the most dangerous one. The checklist itself was deceptively simple:
- Advertise the Service IP from the New PE.
- Withdraw the Service IP announcement from the Legacy PE.
- Flush all FlowSpec redirect rules.
But simple doesn't mean safe. In that sequence, a misconfiguration, a timing issue, or an unexpected BGP convergence behavior could have caused a brief but catastrophic dual-advertisement or a routing black hole. We rehearsed this cutover multiple times in staging, with rollback procedures timed to the second.
The actual cutover took under 3 minutes. The migration path collapsed cleanly, leaving no technical debt, no leftover GRE tunnels, and no static routes.
The result: exactly what a good migration should be: a non-event.
Conclusion
BGP Flowspec has transcended its origins as a blunt instrument for DDoS mitigation. This "Split-Brain" migration demonstrates that Flowspec offers a powerful, programmable interface to the network forwarding plane. By manipulating traffic at the n-tuple level, it enables architectural patterns - such as granular, port-by-port migration of monolithic services - that are simply impossible with standard routing protocols.
But this capability comes with a price. It demands a mature operational environment that treats network configuration as code, robust automation pipelines, and hardware-level safety policies to cage what remains, fundamentally, a "Global Kill Switch."
More than anything, it requires infrastructure courage: the willingness to trust your architecture, your automation, and your team enough to wield battle-tested Flowspec infrastructure with predictable convergence behavior.
Acknowledgments
A special acknowledgment to Jean Lubatti whose leadership made this migration possible. Jean didn't just approve the project - he invested his time to deeply understand its technical complexities. When your manager sits down to debug non-trivial Flowspec rule behavior alongside the engineering team, you know you have something rare: leadership that earns trust by understanding what's actually at stake.

Aurélien Demarty and Kevin Personnic were the essential duo that turned this migration from blueprint into reality. Aurélien's rock-solid Flowspec infrastructure on the backbone gave us the battle-tested foundation and confidence to attempt this migration. Kevin brought irreplaceable tribal knowledge of our legacy network - the kind of expertise you simply can't find in any documentation - combined with deep understanding of the target platform, making him the essential bridge between two worlds.
Ahmet DEMIR and François GOUTEROUX jointly built the automation stack that made this controllable. Together, they created simple, safe interfaces for the platform ops team to manage Flowspec rules without needing to understand the underlying complexity.
And finally, a shoutout to the Juniper MX204 ❤️. Don't let the 1RU form factor fool you - it's hands down the best edge router I've worked with. These machines absorbed DDoS attacks that would bring lesser hardware to its knees, maintained Flowspec rule processing under pressure, and delivered carrier-grade routing without complaint. Proof that serious networks don't require huge rack space.